ChatGPT 大规模封号背后:你的账号为什么会被风控「误伤」?
 2026.06.24 02:43
2026.06.24 02:43 BitBrowser
BitBrowser2026年因环境关联被封禁的Chatgpt账号占比达 38%。平台风控通过浏览器指纹、IP 环境、行为模式锁定账号,正常用户也可能被牵连。这篇详解从风控原理到申诉路径再到环境隔离方案,帮你把误封风险降到最低。

一、风控系统是怎么「认人」的?浏览器指纹、IP、行为三维交叉锁定
很多人收到封号通知后的第一反应是"我没聊敏感话题啊"。
问题是,平台现在判断一个账号"可不可疑",早就超出了内容审核的范畴。OpenAI 的账户安全体系由多层风控构成,其中包括 Cloudflare 的 Bot Management 和 Arkose Labs 的挑战验证,这些系统在用户还没开始打字之前,就已经在评估你的"可信度"了。
评估的依据,主要有三个维度。
1. 浏览器指纹:比密码更精准的设备标识
你在登录 ChatGPT 的时候,网站不只是验证你的邮箱和密码。它会同时采集你浏览器的 Canvas 指纹、WebGL 渲染器信息、字体列表、屏幕分辨率、时区、语言设置。这些参数组合在一起,构成了一个几乎唯一的设备标识。
以 Canvas 指纹为例:网站通过 JavaScript 在隐藏画布上绘制一段文字,然后提取像素数据的哈希值。不同显卡、不同驱动版本、不同操作系统的渲染结果有微小差异,这种差异是稳定的、可重复的,浏览器清理 Cookie 不会影响它。
WebGL 指纹更直接,直接读取你的显卡型号(Renderer)和厂商信息(Vendor)。结合 User-Agent,系统就能判断:你的浏览器声称自己是一台 Windows 笔记本,但 WebGL 渲染器显示的是服务器显卡——这种矛盾在个人用户中几乎不可能出现,一旦出现就会被标记。
2. IP 环境:不是你用的什么 IP,是你的 IP 被什么人用过
数据中心 IP(机房 IP)是最容易触雷的。OpenAI 的风控系统会追踪 IP 段的历史使用记录:如果某个 IP IP 段之前被大量用于自动化注册、批量发帖、恶意爬虫,那么整个 IP 段都会被拉进黑名单。即使你个人没有违规,只要用到了这个段的 IP,就会连带被标记。
WebRTC 泄露也是一个常见触发点。即使配置了代理,浏览器默认的 WebRTC 协议会把你的真实本地 IP 暴露出去。平台同时拿到代理 IP 和真实 IP,发现不一致,直接触发安全审查。
3. 行为模式:你的操作不像一个人
多个账号在同一台设备上切换登录、短时间内从不同地理位置的 IP 登录、操作节奏机械重复——这些都不是正常人类用户的行为特征。OpenAI 的行为分析模型会把这些信号综合起来,一旦超过阈值,自动封号。
信息锚点:OpenAI 在 2024 年第四季度更新的《使用政策》中新增了「禁止通过技术手段规避安全检测」条款,明确将浏览器环境伪造和 IP 伪装列为违规行为。这意味着即使你没有生成违规内容,仅凭"环境看起来不真实"这一点就足以触发封号。关于 ChatGPT 登录和使用中常见的报错类型,可参考 ChatGPT 常见错误码及解决方法。
二、为什么正常账号也会被误封?环境关联的三种典型误判场景
道理说清楚了——平台要封的是"看起来像机器的人"。但问题在于,很多真实用户的浏览器环境也会被误判为"可疑",这就是风控系统的结构性缺陷。
1. 第一种误判:代理 IP 被「连坐」
很多 ChatGPT 用户通过第三方购买的 Plus 账号,本身就绑定了一个共享代理 IP。这个 IP 不是只有你一个人在用——几十上百个用户共用同一个 IP 段,其中只要有人违规(批量注册、滥用 API、发 spam),整个 IP 段就会被标记。你什么都没做,但因为跟违规用户"共享"了 IP 环境,账号就被连带封禁。
我们团队在实际运营中处理过很多这类案例。有意思的是,大部分被封用户根本不了解自己所使用的 IP 到底是什么类型,更不知道这个 IP 的历史使用记录。
2. 第二种误判:浏览器环境的「身份分裂」
举个例子:你在一台 Windows 电脑上通过 Chrome 登录 ChatGPT,但之前在同一台电脑上用 Edge 打开过 ChatGPT 网页版。两个浏览器的指纹完全不同——User-Agent 不同、插件列表不同、字体缓存不同。平台看到"同一个 IP 在短时间内出现两个截然不同的浏览器环境登录同一个账号",这是典型的"账号被盗"信号。
更常见的场景是:办公室电脑 + 家里电脑 + 手机三个设备轮换登录。如果这三个环境的 IP 地点差异很大(比如办公室 IP 在北京、家里 IP 在上海、手机 IP 在海外),平台的行为分析模型会认为这个账号的"移动轨迹"不合逻辑。
3. 第三种误判:Cookie 与缓存的隐性关联
一个容易被忽略的细节是:ChatGPT 的登录页面会同时加载 Google Analytics 和多个第三方追踪脚本。如果你在同一个浏览器里同时登录过多个 ChatGPT 账号,这些追踪脚本生成的 ID 会残留下来。当你登录第二个账号时,平台看到的是"一个新的邮箱,但带着上一个账号的追踪 ID"——直接触发关联判定。
我们踩过这个坑。在测试不同账号环境的时候,因为 Cookie 没有隔离到位,两个测试账号在登录后三小时内双双被封。
三、不止 ChatGPT:电商、社媒、AI 工具批量封号的通用逻辑
ChatGPT 的案例之所以典型,不是因为它特殊,恰恰相反——因为它的封号逻辑代表了一种行业趋势。
1. 亚马逊的关联封店
亚马逊的多账号关联检测跟 ChatGPT 高度同构。卖家账号被关联后,平台不仅封店铺,还会追溯同一个身份下的所有店铺一并处理。判定维度包括浏览器指纹、IP 地址、支付信息、收货地址、操作行为。一旦关联判定成立,几乎不可能申诉成功。
2. Facebook 和 TikTok 的广告账户
社媒平台的广告账户管理是最容易触发批量封禁的场景。一个广告主手里可能有几十个广告账号,用来做 A/B 测试和受众细分。但如果这些账号在同一个设备或同一个 IP 段上操作,平台会在一次风控扫号中把所有账号打包处理。这个损失不是单个账号的损失,是整个广告投放链路的瞬间中断。
3. Google Workspace 和 Claude 等 AI 工具
不只是 OpenAI。Google 的 AI 产品线(Gemini、Vertex AI)也有类似的区域限制和浏览器环境检测。Anthropic 的 Claude 在 2025 年开始加强登录环境验证,使用代理 IP 登录的账号被要求二次验证的概率明显提高。
信息锚点:根据电商合规机构的统计,2024 年因"环境关联"导致的跨境卖家账号封禁占了总封禁量的 38%,超过了因产品质量问题和物流时效被处罚的比例之和。这个数字在 2023 年还只有 24%。这也意味着:卖家投入最多精力优化的产品和物流,两项加起来的封店风险都没有环境关联一项高——跟大多数运营者的直觉完全相反。
这是一种全局趋势:平台不再满足于"内容审核",而是从底层环境开始做风控。多账号运营如果要持续,环境隔离不再是可选项,而是必选项。
四、怎么避免被「误伤」?多账号环境隔离的四步防护方案
说到底,风控系统的逻辑是:如果两个账号看起来来自同一台设备,它们就是同一个人。所以防护的核心逻辑也很直接:让每个账号在平台眼里都像一台独立的真实设备。
第一步:为每个账号绑定独立的 IP
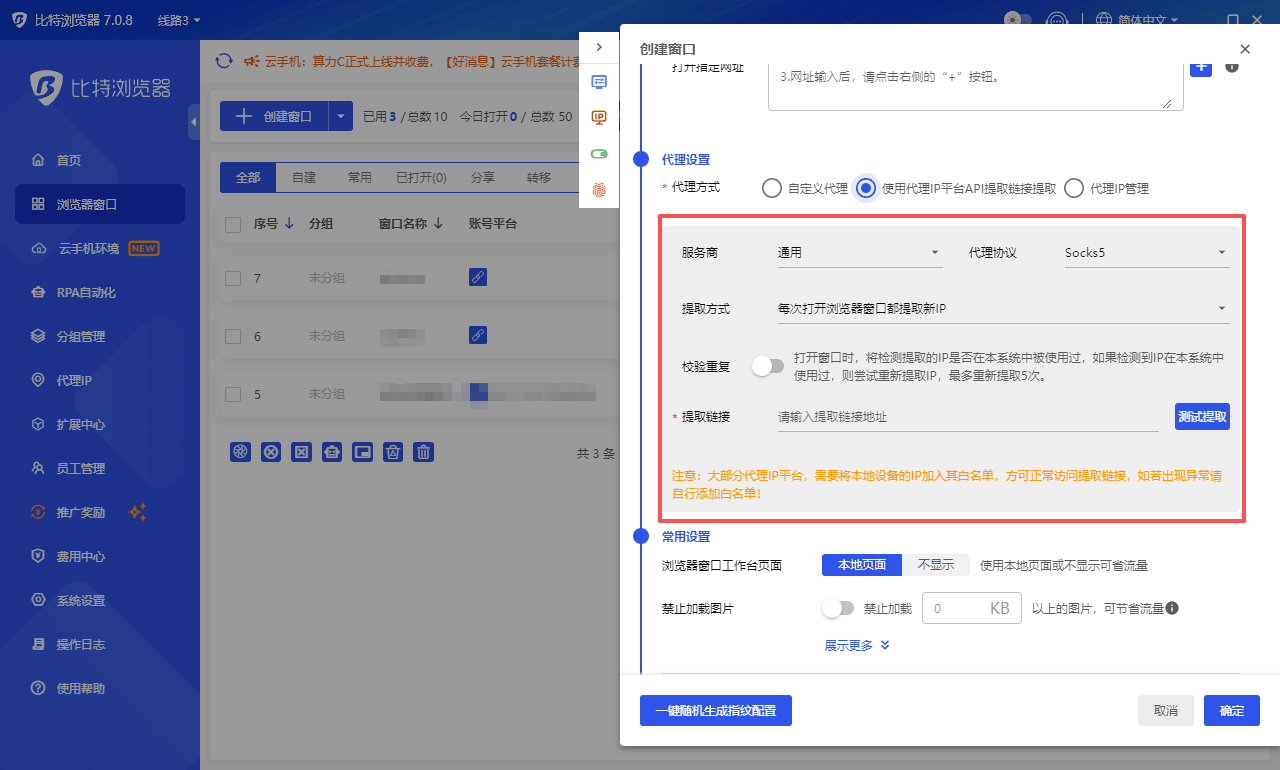
不要再让多个账号共用同一个代理 IP。一个账号一个 IP,且优先选择住宅 IP。数据中心 IP 虽然便宜,但被标记的概率太高,省下来的 IP 费用可能被一个封号事件全部抵消。
配置完成后,在浏览器环境里打开 ipinfo.io 或 whoer.net 确认检测结果。重点看两个指标:IP 类型是否为 Residential(住宅)而非 Hosting(机房),以及黑名单分数是否为 0。关于不同代理类型的配置细节和实际效果对比,可以参考这篇 如何隐藏真实 IP 地址。
第二步:固定登录环境,不跳变
新注册或新恢复的账号,头 5-7 天不要切换登录设备和网络环境。平台对"新号"的风控阈值远高于老号——一个新号在 24 小时内从三个不同 IP 地址登录,大概率会被判定为被盗或滥用。环境稳定是第一优先级。
第三步:隔离每个账号的浏览器指纹
这是最关键的一步。每个账号需要拥有独立的浏览器指纹参数:User-Agent、Canvas 哈希值、WebGL 渲染器信息、字体列表、屏幕分辨率、时区、语言设置。所有参数之间必须逻辑自洽——时区和语言要和 IP 地理位置匹配,User-Agent 要和系统的硬件信息匹配。
做完配置后,去 BrowserLeaks(来源:https://browserleaks.com/)跑一遍完整检测。如果任意两个环境的 Canvas 哈希值或 WebGL 渲染器信息完全一致,说明指纹隔离没生效,需要重新配置。如果需要从零开始搭建多账号环境,建议先通读 多账号浏览器完整使用指南,建立完整的配置框架再动手。
第四步:彻底隔离 Cookie、缓存和本地存储
Cookie 隔离不是简单地"清掉就行"——要确保不同账号之间不存在任何共享的追踪标识。包括 Google Analytics ID、Facebook Pixel 数据、广告联盟 Cookie 等第三方追踪脚本生成的数据,全部需要独立存储。
在工具层面,这意味着每个账号环境必须使用完全独立的用户数据目录。如果用的是普通浏览器手动管理,每次切换账号要重启浏览器并清空所有站点数据,成本太高,几乎不可持续。
五、工具落地:比特浏览器如何从环境层切断关联风险
前面四步把原理和操作要点说清楚了,但说实话,手工维护几十个账号的独立环境是一件重复且容易出错的事——每个环境要单独配 IP、调指纹参数、跑验证测试,一旦数量上来,漏一个参数就可能触发风控。
这也是为什么指纹浏览器会成为多账号运营的标配。
1. 环境隔离的自动化实现
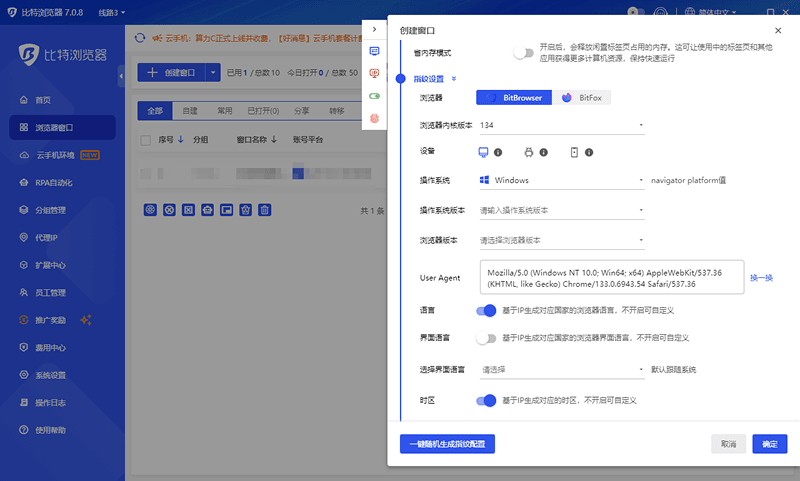
比特浏览器 的设计思路是把前面四步配置全部自动化:每创建一个浏览器环境,系统自动分配独立的 Cookie 存储空间、独立的缓存目录、独立的本地存储(LocalStorage)、独立的浏览器指纹参数。用户不需要手动去管这些隔离细节,只需要创建环境、绑定 IP、启动即可。
对于需要大量管理的场景,比特浏览器支持 CSV 表格批量导入环境,一行对应一个账号,自动生成独立配置,不需要逐个手动操作。
2. 指纹防护的真实效果
比特浏览器的指纹引擎覆盖了 Canvas、WebGL、AudioContext 三个平台高频检测维度。具体来说:
・Canvas 防护:在渲染结果中注入微量噪声,让每个环境产生不同的哈希值,且噪声模式模拟真实显卡差异
・WebGL 防护:从真实设备数据库中采样渲染器和厂商信息,确保参数之间统计上自洽,不出现"Windows UA + Mac 显卡"的矛盾
・AudioContext 防护:修改音频信号处理参数,生成差异化的音频指纹,覆盖近年新增的检测维度
这些对普通用户来说是不可见的底层处理,但它们决定了平台看到的"你"是否像一个真人。
3. 日常使用中的易忽略配置
有几个配置在使用中特别容易漏掉,值得单独说:
1. WebRTC 替换
比特浏览器内置了 WebRTC 替换功能,确保即使浏览器发起 STUN 请求,也不会泄露本地真实 IP。这个开关默认建议开启。
2. 时区与 IP 的自动对齐
手动配时区很容易出错——代理 IP 在美西,时区设成了北京。比特浏览器的做法是自动检测代理 IP 的地理位置并同步时区和语言设置,减少人工配错的可能。
3. 窗口同步操作的随机化
如果需要在多个账号上执行相同操作(比如多个社媒账号同步更新),比特浏览器的窗口同步功能会在每个窗口的操作中注入随机的时间偏移和轨迹变化,让操作看起来不完全一致,降低行为关联风险。
4. 团队场景下的权限控制
如果是团队共用一套账号,权限管理需要细粒度控制。比特浏览器支持按环境分配查看/编辑权限,操作日志全程记录——哪个成员在什么时间登录了哪个环境、执行了什么操作,全部可追溯。
常见问题解答
Q:ChatGPT 账号被封之后还能申诉回来吗?
可以,但要看封号原因。如果是"违反使用条款"(terms of use violation),申诉难度很高。如果是"suspicious activity"或"unusual activity"类型的封号,通常跟环境检测有关,申诉成功率更高。申诉路径:通过 OpenAI Help Center 提交工单,选择"Account Deactivated"类别,在描述中说明自己的使用场景是个人学习/工作,强调没有自动化脚本操作和账号共享。注意:申诉期间不要在同一个 IP 环境注册新账号,否则会被"封号链"连带处理。
Q:有没有免费的工具能解决 ChatGPT 的环境登录问题?
ChatGPT 的网页版对浏览器环境的检测相对轻量,如果只有一个账号,用 Chrome 无痕模式 + 固定住宅 IP 基本够用。但如果管理多个账号、或者涉及电商/社媒等对指纹检测更严格的平台,免费方案很难覆盖所有维度。比特浏览器提供 10 个免费浏览器环境,覆盖 Canvas、WebGL、AudioContext 指纹防护和 Cookie 隔离,适合刚起步的团队先跑通流程。
Q:用指纹浏览器算「规避安全检测」吗?OpenAI 会因此封号吗?
OpenAI 的条款禁止"规避安全检测"(circumventing safety features),但指纹浏览器的定位不是"规避"而是"环境隔离"——让每个账号在独立的、真实的浏览器环境中运行,这与恶意伪造指纹、批量注册账号有本质区别。关键看用途:如果你是正常的多账号管理(比如团队共用、多项目管理),使用合规;如果用于批量注册、API 滥用、垃圾内容生成,不管用不用指纹浏览器都会被封。
Q:多台物理设备隔离 vs 指纹浏览器,哪个更不容易被误封?
物理设备隔离在理论上更可靠,因为每台设备的硬件指纹天然唯一且不可控。但问题在于成本:10 个账号需要 10 台设备,100 个账号需要 100 台设备,对绝大多数团队来说不现实。指纹浏览器做到"接近物理设备隔离"的效果是可行的,前提是指纹参数足够真实且逻辑自洽——不出现"Windows UA + Mac 显卡"这类矛盾。
Q:代理 IP 选住宅 IP 还是数据中心 IP?有没有中间方案?
优先级:住宅静态 IP > 住宅动态 IP > 数据中心独享 IP > 数据中心共享 IP。如果预算有限,至少做到"同一批账号不共用同一段 IP"。中间方案是 4G/5G 移动流量卡——每个账号绑定一张卡,IP 由运营商动态分配,虽然也会变化但 IP 类型是真实的移动网络 IP,比机房 IP 的信任度高。
Q:能不能在验证环境配置后,确认自己不会被误封?
不能 100% 保证,但可以把风险降到最低。验证清单:(1) 每个环境的 Canvas 哈希值互不相同;(2) WebGL 渲染器信息与 User-Agent 匹配;(3) WebRTC 不泄露真实 IP;(4) 时区和语言与代理 IP 地理位置一致;(5) 代理 IP 的黑名单分数为 0。满足这五条,被浏览器环境维度误判的概率就很低了。剩余风险主要在行为模式层——操作节奏不能太机械。
Q:如果已经因为环境问题被封了一批账号,原来的数据还能找回吗?
ChatGPT 被封账号的聊天记录和自定义 GPT 数据通常无法直接导出。OpenAI 的封号信件里偶尔会提供数据导出窗口(一般 30 天内),但这不是保证的。为了避免数据损失,建议养成定期备份习惯:ChatGPT 的聊天记录可以通过设置中的"数据导出"功能定期下载。电商和社媒平台也是一样——不要把账号本身当作唯一的数据存储点。
 双端协同,多开账号
双端协同,多开账号 丰富的指纹配置,有效防关联
丰富的指纹配置,有效防关联 多员工协同管理,高效运营
多员工协同管理,高效运营推荐文章
查看更多 ![]()