Python爬虫如何突破验证码?5种主流反爬机制深度解析
 2026.05.20 08:46
2026.05.20 08:46 BitBrowser
BitBrowser简单的数字与字母识别早已成为过去式。如果你还在用基础的 Python requests 配合简单的伪装去抓取数据,大概率会被无处不在的验证码死死拦在门外。
现代网络防护系统(如 Google、Cloudflare 部署的最新验证机制)不再仅仅测试你“能不能认出这张图”,它们已经进化成了复杂的行为与环境监测系统。可见的图形验证只是最后一道防线,真正的较量在后台:它们在疯狂分析你的浏览器指纹、网络请求特征以及历史行为轨迹。
对于从事自动化测试、电商数据采集以及多平台账号矩阵运营的开发者来说,深入理解这些底层机制是业务存活的关键。本文将为您详细扒开现代验证码的工作逻辑,并分享目前业内最高效的验证码绕过与突破策略。

一、为什么你的爬虫总被拦截?
要打败敌人,首先要了解敌人。目前的验证码系统实际上是一套风险评分模型。以下是目前三种最具代表性且技术最顶尖的解决方案:
1. reCAPTCHA v3 (Google):
这是一种几乎完全隐形的评分模型。当你访问网页时,reCAPTCHA v3 不会弹出拼图,而是在后台收集你的行为数据,并向网站服务器返回一个 0.0(机器人)到 1.0(真实人类)的风险评分。
・致命打击点:它的评分极度依赖你在 Google 生态中的数字足迹。如果你使用没有任何历史 Cookie、未登录过 Google 账号的纯净爬虫环境,或者 IP 位于机房(数据中心),得分通常会直接低于 0.3,从而遭到彻底封杀或被降级为极难的图片点击验证。
2. Cloudflare Turnstile:
很多时候你只会看到页面上转了一圈绿色的勾,没有任何交互。但在这短暂的几秒内,Turnstile 已经完成了海量的测试:
・致命打击点:它会下发基于哈希计算的“工作量证明”(Proof of Work),消耗你脚本的 CPU 算力,增加自动化成本。更可怕的是,它会深度核对你的环境完整性(Canvas、WebGL、WebAudio API 的渲染特征是否与声明的 User-Agent 匹配)。如果你的自动化脚本运行在阉割版的浏览器内核上,这一关必败无疑。
3. hCaptcha:高强度的视觉对抗系统
hCaptcha 是 Google 的有力竞争者,在检测到可疑流量时,它提供的图像识别任务往往比 Google 更加刁钻。
・致命打击点:极度依赖鼠标行为轨迹与 IP 质量。如果鼠标移动轨迹是直线的、没有人类应有的随机微抖动,系统会不断要求你识别更多的图片,陷入死循环。
二、突破验证码封锁的 5 种主流技术方案
针对上述复杂的反爬机制,开发者通常需要根据流量规模、并发需求和预算,采用不同的反制策略。
1. 第三方 API 委托打码(适用于高并发场景)
这是最主流且易于扩展的方案。你无需自己在本地消耗显卡算力,只需将获取到的验证码数据或网页环境发送给第三方打码平台,他们会返回一个 Token。
・关键细节:拿到 Token 后不能直接结束,你必须找到网页中的隐藏字段,将 Token 注入,并使用 JavaScript 触发网站的回调函数,否则提交按钮依然是灰色的。
・避坑指南:你的爬虫所使用的 User-Agent 和代理 IP,必须与打码服务在获取 Token 时使用的完全一致,否则由于信息错位,Token 会被判定为伪造。
2. 底层 HTTP 请求与 TLS 指纹伪装
很多时候你的 Python 爬虫还没看到验证码,连接就被切断了。这是因为 Python 原生的 requests 库在发起 HTTPS 请求时,其 TLS 握手特征与真实的 Chrome/Firefox 截然不同。
・解决方案:抛弃原生 requests,改用能够模拟真实浏览器 TLS 指纹的网络库。只要底层的 TLS 指纹与真实浏览器一致,很多初步的拦截机制就会失效。
3. 基于机器学习与 OCR 的本地识别
如果你面对的是传统的文字验证码或滑块拼图,内部构建识别器可以节省大量 API 费用。
・文本验证码:使用 Python 的 Pillow 库进行灰度化与二值化处理,去掉干扰线后,交给 Tesseract OCR 引擎提取字符。
・复杂扭曲字符:引入轻量级的 CNN(卷积神经网络)模型。通过多层卷积提取特征并配合全连接层,可以精准应对高度粘连和扭曲的验证码。
・滑块验证码:利用 OpenCV 进行边缘检测(Canny 算法),计算出滑块需要移动的真实距离,再配合代码自动拖拽。
4.高仿真的行为轨迹模拟
当使用 Selenium 等自动化工具时,必须抹除掉机器人的痕迹。
・核心动作:通过注入 JavaScript 代码,抹去浏览器 navigator.webdriver 属性。
・操作拟人化:利用 ActionChains 进行拖动时,务必加入非线性的物理缓冲逻辑。先快后慢,并引入毫秒级的随机暂停,拒绝机械式的匀速直线滑动。
5. 使用指纹浏览器彻底重构环境(强烈推荐)
常规的 Puppeteer 或 Selenium 纵使加了 stealth 插件,在遇到极度严苛的 Cloudflare 检测时依然可能翻车。因为很多反制手段仅仅是在 JS 层面对参数进行修饰,而高阶反爬会直接探测浏览器内核底层的真实硬件反馈。
如果你需要进行大规模数据采集、海外电商抢单或多社交账号矩阵运营,使用物理级隔离的指纹浏览器才是目前一劳永逸的最佳策略。在此,我们重点推荐业内表现优异的比特浏览器(BitBrowser)。它能够从源头上解决设备指纹暴露的问题,具有极高的性价比和防检测能力:
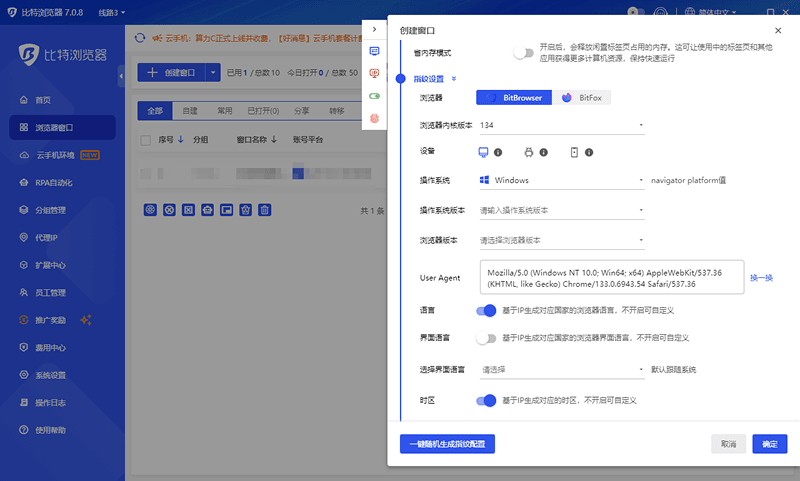
1. 物理级指纹深度伪装:比特浏览器基于深度的 Google 和 Firefox 双内核开发,每个浏览器窗口都会生成一套完全独立的硬件参数。这保证了各个窗口之间100% 物理隔离,让目标网站判定你来自全球各地真实用户的不同设备。
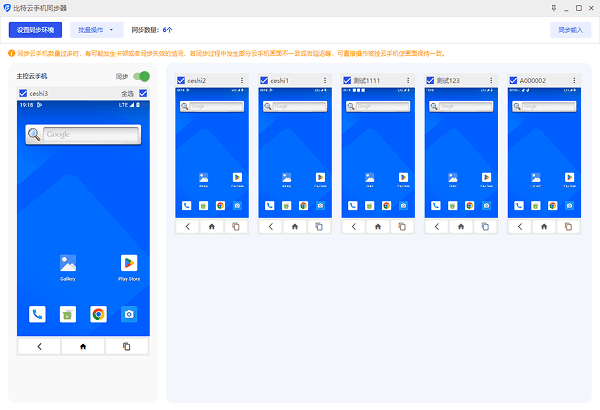
2. 独家云手机生态:移动端抓取是当下的难点。比特浏览器不仅支持电脑网页环境隔离,更提供了安卓环境的云手机模拟器,支持批量管理强依赖移动端的 App 数据抓取,这在同类产品中极具优势。
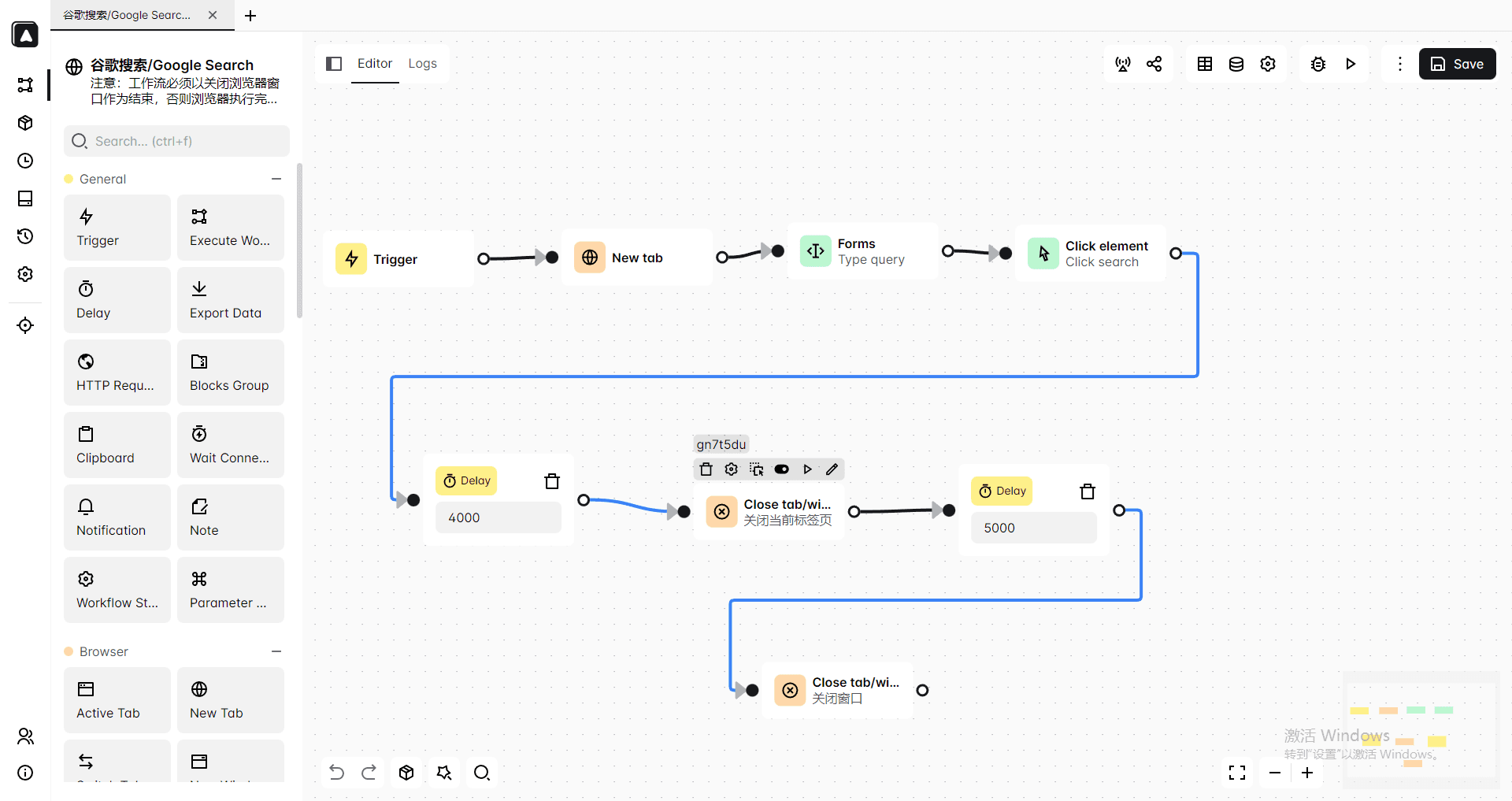
3. Local API 与 RPA 自动化支持:作为开发者,你可以轻松利用比特浏览器提供的本地 API 接口,通过 Python 或 Go 脚本批量控制环境的启动、Cookie 的注入和页面的访问。不懂代码的运营人员也可以使用其内置的RPA 机器人流程自动化功能,直接录制点击、滑动轨迹并批量执行。
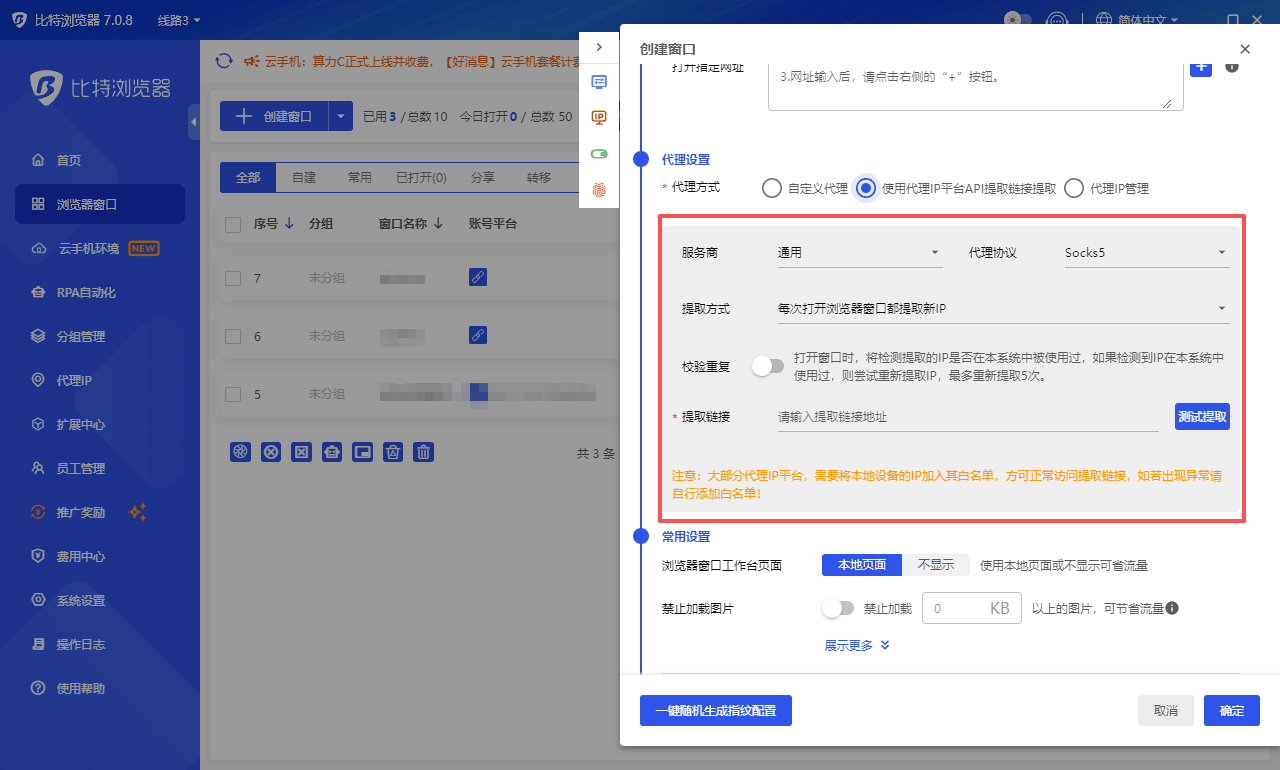
4. 全球代理 IP 无缝集成:支持自定义绑定各类代理。浏览器会自动根据你填写的 IP 匹配当地时区与语言配置,杜绝低级特征泄露。
5. 永久免费额度:比特浏览器极其良心地提供了10 个永久免费的独立环境配置额度,对于小型爬虫项目或开发者前期跑通业务模型来说,毫无成本压力。
三、爬虫被封禁的常见原因自查清单
如果你明明使用了高级技术或打码平台,依然无法成功获取数据,问题往往出在以下这几个容易忽视的细节上:
・节点 IP 太“脏”:这是重灾区。机房代理早已在各大反作弊系统内部标红。请务必切换至动态住宅代理或移动端代理。
・HTTP 请求头顺序错乱:真实的 Chrome 浏览器发出的 Request Headers 顺序是固定的。如果你的代码库随意拼接请求头,乱序的 Header 宛如在向服务器高呼“我是脚本”。
・缺乏账号环境的长期养成:在应对 reCAPTCHA v3 时,如果你拿着一个没有任何历史缓存和浏览记录的“全新”环境去访问,评分必定极低。请使用比特浏览器这类工具提前导入目标站点的长期 Cookie,这相当于给你的机器人套上了“良民证”。
四、写在最后
单纯依靠破解图形验证码的野蛮爬取时代早已结束。现代网络数据采集是一场关于信誉度、环境一致性以及行为轨迹拟真的综合博弈。
无论是定制底层 TLS 请求、训练深度学习模型,还是借助比特浏览器(BitBrowser)搭建彻底隔离的高防伪装环境,我们的核心逻辑始终不变:尽可能将自动化程序的数字指纹融入真实用户的海洋之中。
最后需要提醒的是,在进行自动化网络抓取时,请务必遵守目标网站的 robots.txt 协议与当地的数据合规要求,合理控制请求频率,避免对目标服务器造成恶意过载。掌握技术不仅是为了突破边界,更是为了构建高效、可持续的数据生态。
 双端协同,多开账号
双端协同,多开账号 丰富的指纹配置,有效防关联
丰富的指纹配置,有效防关联 多员工协同管理,高效运营
多员工协同管理,高效运营推荐文章
查看更多 ![]()